The China Biographical Database Project is a freely accessible relational database with biographical information about approximately 370,000 people, primarily from the 7th through 19th centuries. In our efforts to populate it with biographical data, we are using MARKUS for tagging historical Chinese texts and identifying information about historical figures that we can put into our database. From 2015 onwards, we have tagged persons’ names and government office titles in epitaphs (muzhiming 墓志銘) from Tang China (618-907 AD) as well as the Compilation of Song Regulations 宋會要輯稿, which is a collection of official documents from the 10th to the 13th centuries.
In our work on Tang epitaphs, we employ regular expressions to batch tag persons’ names and office titles mentioned in such epitaphs. After doing that we adjust the regular expressions to reduce errors due to irregularities in the text to a workable amount, we load the tagged texts onto MARKUS. Our helpers then use it to check whether the persons’ names and office titles are tagged accurately. Each of our helpers is assigned a number of epitaphs. The batch uploading function on MARKUS enables us to load all the epitaphs that we need to process for the project. After these checks are done, they can also batch download the data instead of downloading them one by one. After finishing these checks, we use a tailored Python program to extract all the persons’ names in an epitaph and create temporary IDs for those persons. Then our helpers will use MARKUS to create connections between those names and temporary IDs. (See figure 1) With this we obtain the names and office titles for those historical figures, which we will include in CBDB.
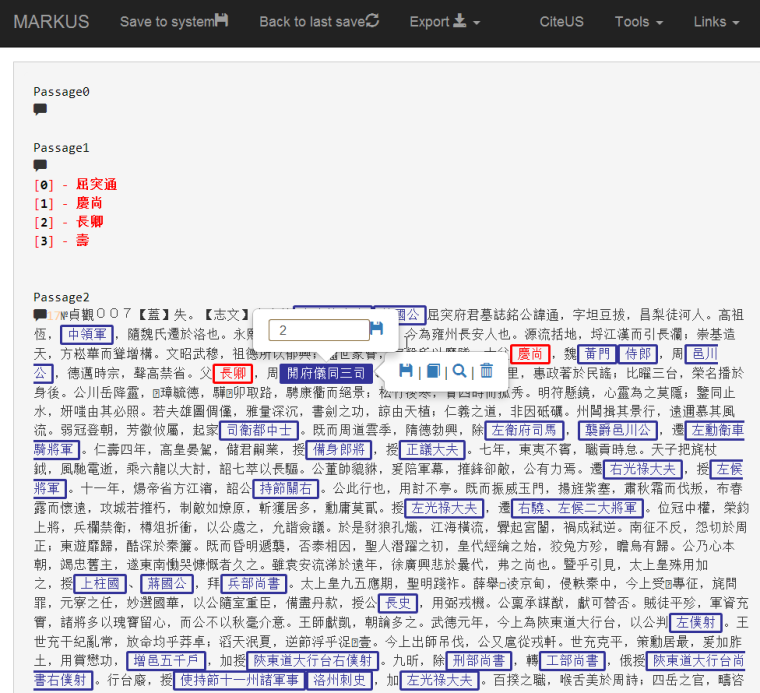
Figure 1, creating the relationships between office titles and person names
In our work on the Compilation of Song Regulations, we are implementing a similar solution. But there are two main differences. First, the texts from Compilation of Song Regulations that we use are XML files drawn from an online tagging analysis platform developed by the National Taiwan University's Compilation of Song Regulations System. The tags used by their system are quite different from the ones on MARKUS. Thus we developed a Python program to convert those tags to adhere to MARKUS standards. (See Figure 2) Secondly, since the biographical data that the Compilation of Song Regulations contains are much more numerous than in Tang epitaphs, we do not ask our helpers to link persons’ names to office titles manually. Instead we designed an artificial intelligence (AI) system to determine the probabilities of the relationships between persons’ names and office titles after we finish our training data. In this AI system, we have created some patterns to define the relationship between office titles and persons’ names within a paragraph in the Song Regulations text. For example, if there is an office title at the beginning of a paragraph, and if a list of persons’ names follow it, it probably means that the office titles should be assigned to each of the persons’ names behind it. We have already figured that this is the general pattern for many paragraphs in the text. By identifying this pattern, we associate historical persons with the office titles in such government records. This training data will be sent to the team developing MARKUS for further improving its machine learning function.
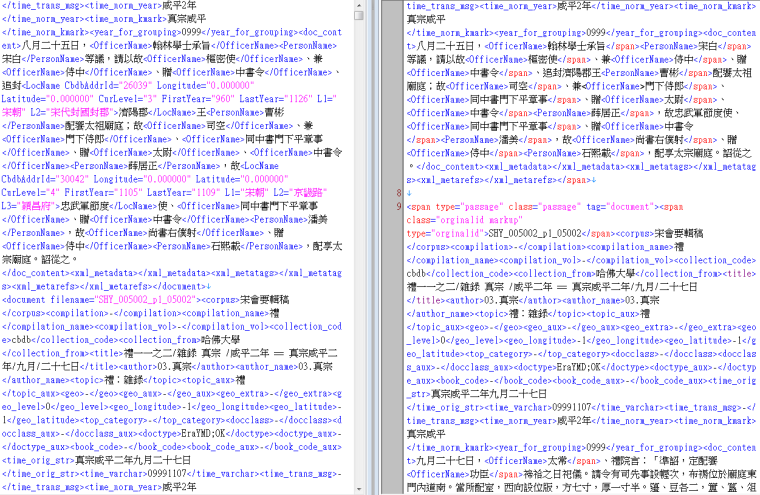
Figure 2, National Taiwan University's Compilation of Song Regulations System tag format
Hongsu Wang, Project Manager, The China Biographical Database, Harvard University, [email protected]
Lik Hang Tsui, Postdoctoral Fellow, The China Biographical Database, Harvard University, [email protected]